First of all, I'm assuming that with "draw calls", you mean the command that tells the GPU to render a certain set of vertices as triangles with a certain state (shaders, blend state and so on).
Draw calls aren't necessarily expensive. In older versions of Direct3D, many calls required a context switch, which was expensive, but this isn't true in newer versions.
The main reason to make fewer draw calls is that graphics hardware can transform and render triangles much faster than you can submit them. If you submit few triangles with each call, you will be completely bound by the CPU and the GPU will be mostly idle. The CPU won't be able to feed the GPU fast enough.
Making a single draw call with two triangles is cheap, but if you submit too little data with each call, you won't have enough CPU time to submit as much geometry to the GPU as you could have.
There are some real costs with making draw calls, it requires setting up a bunch of state (which set of vertices to use, what shader to use and so on), and state changes have a cost both on the hardware side (updating a bunch of registers) and on the driver side (validating and translating your calls that set state).
But the main cost of draw calls only apply if each call submits too little data, since this will cause you to be CPU-bound, and stop you from utilizing the hardware fully.
Just like Josh said, draw calls can also cause the command buffer to be flushed, but in my experience that usually happens when you call SwapBuffers, not when submitting geometry. Video drivers generally try to buffer as much as they can get away with (several frames sometimes!) to squeeze out as much parallelism from the GPU as possible.
You should read the nVidia presentation Batch Batch Batch!, it's fairly old but covers exactly this topic.
总结就是 合并draw call 可以让 GPU 负载更多算力,而不是CPU . (GPU空转的比较多,一般都在等待CPU提交数据命令)
因此, draw call 多的话, CPU 需要承担更多计算,容易发热.
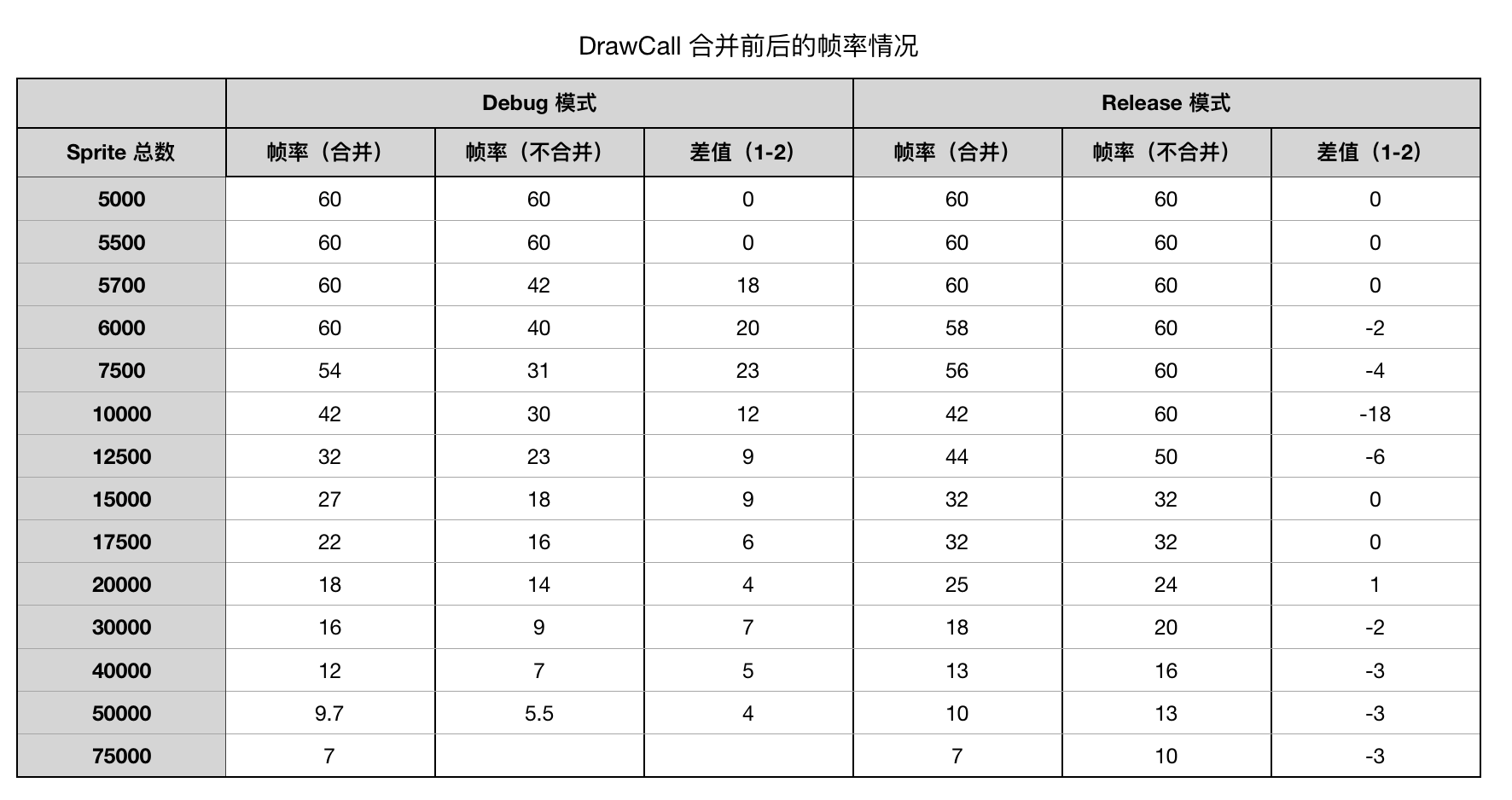
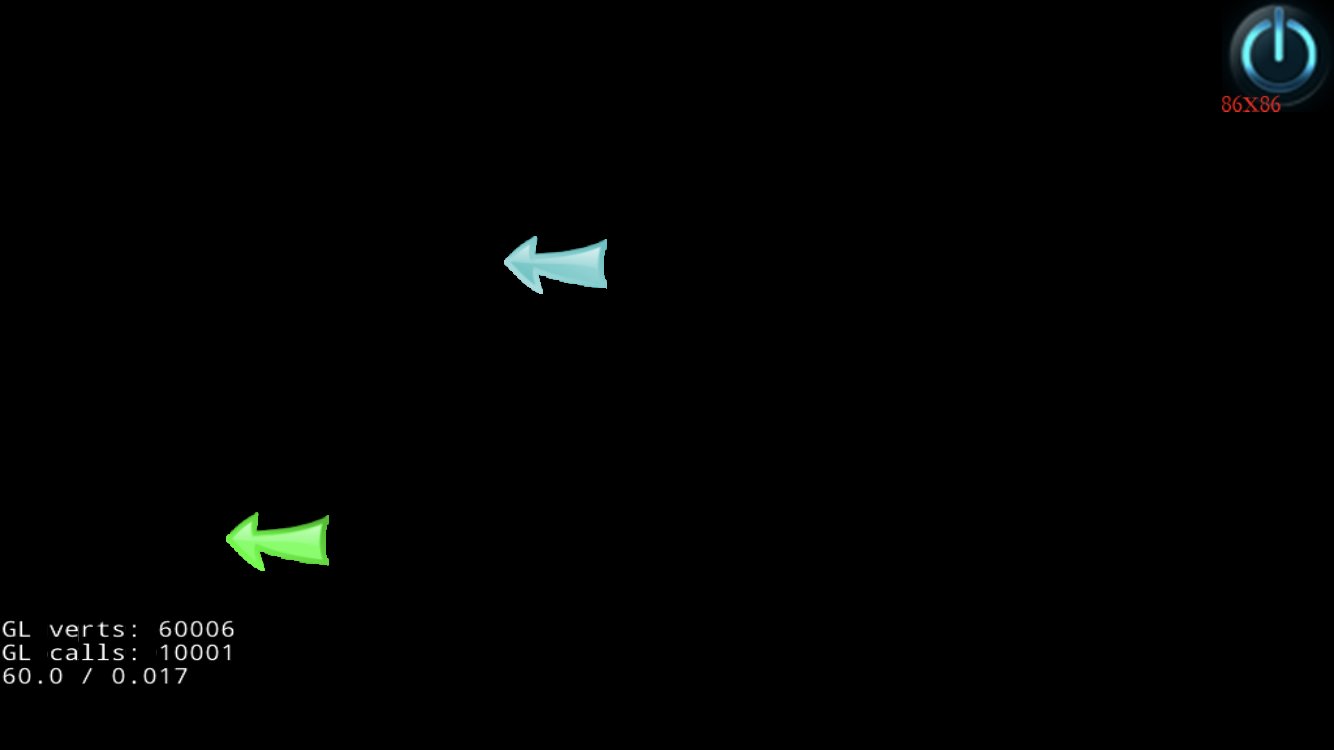
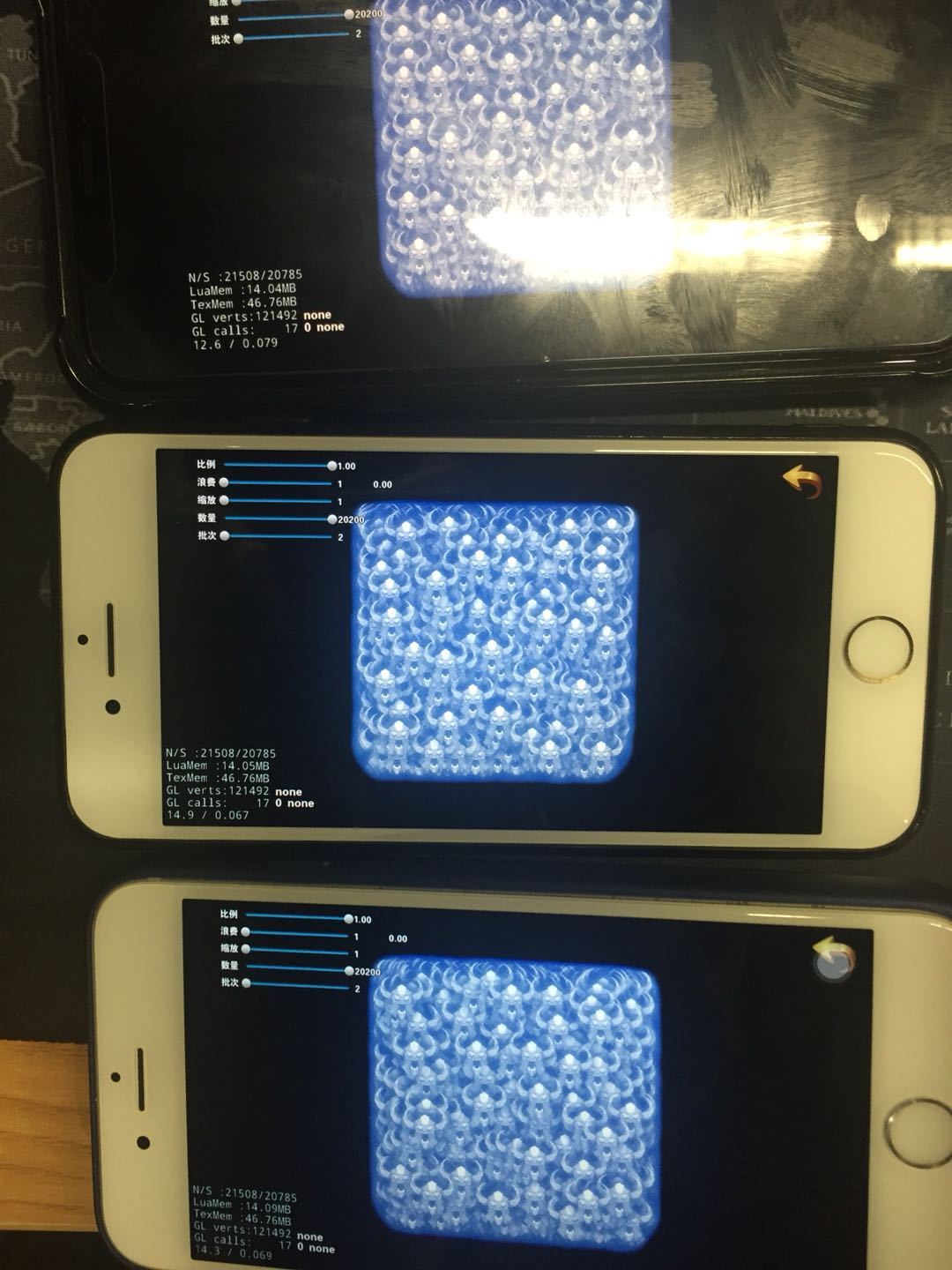
上面测试的帧率变化不大,是因为即使不合并 draw call , 所增加的额外 CPU 计算也没有超过它的处理频率.